Preprocessing
Datasets were pre-processed using commonly accepted procedures, including background correction, normalisation, summation and log-transformation. XPN batch correction was applied to merge Affymetrix and Illumina data in the Edinburgh L23 dataset (Turnbull et al 2012). Datasets were median-centered and scaled to a [-1 to 1] range. For Edinburgh RS and L23 datasets the signatures were translated from Affy U-133 IDs into the namespace of the datasets.
Iterative Consensus PAM
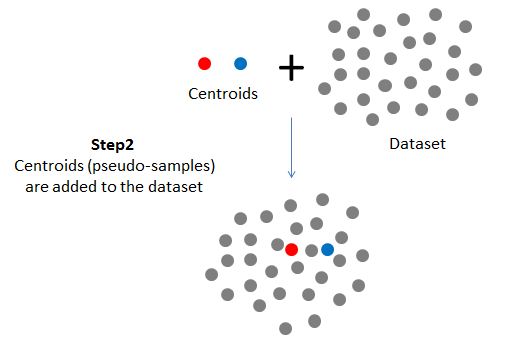
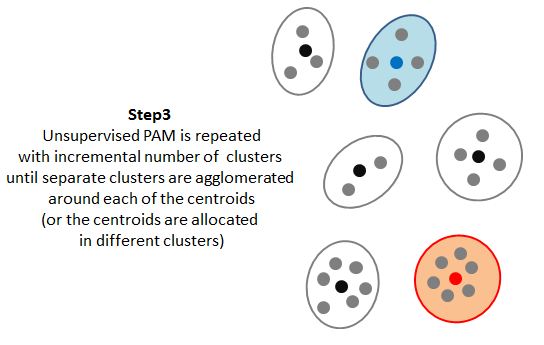
The classification algorithm is illustrated on the figure below. It includes the following steps: Step 1: A pathway's signature is used to construct two pseudo-samples (centroids): one centroid corresponding to the active state of the pathway and the other centroid corresponding to the inactive state of pathway. Step 2: The centroids are added to the datasets. Step 3: The datasets are subjected to unsupervised partitioning using PAM (as implemented in Cluster R-package). Unsupervised PAM is repeated with incremental number of clusters until separate clusters are agglomerated around each of the centroids (or the centroids are allocated in different clusters). Step 4: The above procedure is repeated with three different distance metrics: Euclidian, Manhattan and Spearman correlation. Consensus between all three metrics is used for the final class allocations.